Celery的介绍
什么是Celery?
Celery是一个简单、灵活可靠、能处理大量消息的分布式系统。它是一个专注于实时处理的任务队列,并且也支持任务调度。Celery有广泛的用户与贡献者社区,而且是开源的,使用 BSD许可证 授权。
何为任务队列
任务队列是一种在线程或机器间分发任务的机制。
消息队列的输入是工作的一个单元,成为任务,独立的职程(worker)进程持续监视队列中是否有需要处理的新任务。
Celery用消息通信,通常使用中间人(broker)在客户端和职程间斡旋。这个过程从客户端向队列现价消息开始,之后中间人把消息派送给职程。
Celery系统可包含多个职程和中间人,以此获得高可用和横向扩展能力。
Celery是用Python编写的,但协议可以用任何语言实现。迄今,已有Ruby实现的RCelery、node.js实现的node-celery以及一个PHP客户端,语言互通也可以通过using webhooks实现。
celery工作流程图如下: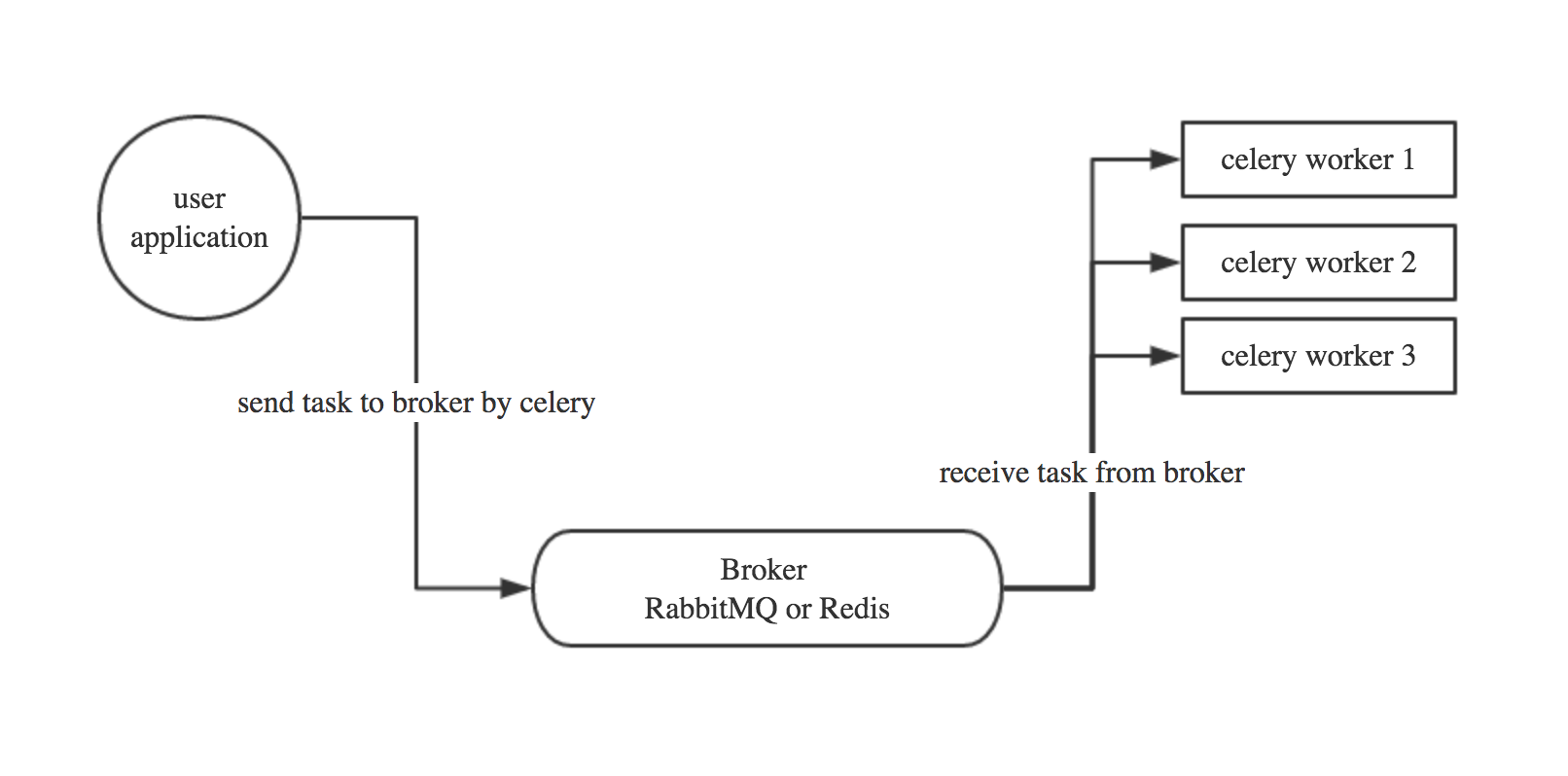
安装
你可以从Python Package Index(PyPI)或源码安装Celery。1
2
3$ pip install -U Celery
或
$ easy_install -U Celery
源码安装:1
2
3
4$ tar xvfz celery-0.0.0.tar.gz
$ cd celery-0.0.0
$ python setup.py build
$ python setup.py install
注:如果不是在virtualenv里安装,最后一条命令必须以管理员权限执行。
Celery的优点
简单
Celery易于使用和维护,并且它不需要配置文件。下面是一个你可以实现的最简应用:1
2
3
4
5from celery import Celery
app = Celery('hello', broker='amgp://guest@localhost//')
def hello():
return 'hello world'高可用性
倘若连接丢失或失败,职程和客户端自动重试,并且一些中间人通过主/主 或 主/从 方式复制来提高可用性。快速
单个Celery进程每分钟可处理数以百万计的任务,而保持往返延迟在亚毫秒级。灵活
Celery几乎所有部分都可以扩展或单独使用。可以自制连接池、序列化、压缩模式、日志、调度器、消费者、生产者、自动扩展、中间人传输或更多。
Celery支持中间人
- RabbitMQ, Redis
- MongoDB(实验性), ZwroMQ(实验性)
- CouchDB(实验性), SQLAlchemy(实验性)
- Django ORM(实验性), Amazon SQS(实验性)
- 还有更多…
- 并发
- prefork(多进程)
- Eventlet, gevent
- 多线程/单线程
- 结果存储
- AMQP, Redis
- memcached, MongoDB
- SQLAlchemy, Django ORM
- Apache Cassandra
- 序列化
- pickle, json, yaml, msgpack
- zlib, bzip2压缩
- 密码学消息签名
框架继承
Celery通常与Web框架继承,其中的一些甚至已经有了集成包:
| 框架 | 名称 |
|---|---|
| Django | django-celery |
| Pyramid | pyramid_celery |
| Pylons | celery-pylons |
| Flask | 不需要 |
| web2py | web2py-celery |
| Tornado | tornado-celery |
继承包并非是严格必要的,但他们让开发更简便。
中间人(非实验性)
使用 RabbitMQ
安装与配置
RabbitMQ是默认的中间人,所以除了需要你要使用的中间人实例的URL位置,它并不需要任何额外的依赖或起始配置:1
BROKER_URL = 'amqp://gueest:guest@localhost:5672//'
Celery中间人URL的描述和完整的中间人可用配置选项列表见 Broker Settings安装
RabbitMQ服务器1
sudo apt install rabbitmq-server
设置
RabbitMQ
要使用Celery,我们需要创建一个RabbitMQ用户、一个虚拟主机,并且允许这个用户访问这个虚拟主机:1
2
3sudo rabbitmqctl add_user myuser mypassword
sudo rabbitmqctl add_vhost myvhost
sudo rabbitmqctl set_permissions -p myvhost myuser ".*" ".*" ".*"
使用 Redis
安装
1
2
3sudo apt install redis-server
或
pip install -U celery[redis]配置
配置非常简单,只需要设置Redis数据库的位置:1
BROKER_URL = 'redis://localhost:6379/0'
URL 的各式为:
1
redis://:password@hostname:port/db_number
应用
首先你需要一个Celery实例,成为Celery应用或直接简称应用。既然这个实例用于你想在Celery中做的一切事——比如创建任务、管理职程的入口点,它必须可以被其他模块导入。
在此教程中,你的一切都容纳在单一模块里,对于更大的项目,你会想创建独立模块。
创建tasks.py,示例如下:1
2
3
4
5
6from celery import Celery
app = Celery('tasks', broker='amqp://guest@localhost//')
def add(x, y):
return x + y
Celery的第一个参数是当前模块的名称,这个参数必须有。第二个参数是中间人关键字参数,指定你所使用的消息中间人的URL,此处使用了RabbitMQ你可以写amqp://localhost,而对于Redis你可以写redis://localhost
你定义了一个单一add任务,返回两个数的和。
运行Celery职程服务器
你现在可以用worker参数执行我们的程序:1
celery -A tasks worker --loglevel=info
调用任务
你可以用delay()方法来调用任务。
这是apply_async()方法的快捷方式,该方法允许你更好地控制任务执行:1
2>>> from tasks import add
>>> add.delay(4, 4)
保存结果
如果你想要保持追踪任务的状态,Celery需要在某个地方存储或者发送这些状态。可以从内建的几个结果后端选择:SQLAlchemy/Django ORM、Memcached、Redis、AMQP(RabbitMQ)或MongoDB,或者你可以自制。如下面的例子:1
app = Celery('tasks', backed='amqp', broker='amqp://')
或者如果你想要把Redis用作结果后端,但仍然用RabbitMQ作为消息中间人:1
app = Celery('tasks', backend='redis://localhost', broker='amqp://')
调用任务:1
result = add.delay(4, 4)
read()方法查看任务是否完成处理:1
2result.ready()
False
更多信息请参照 Celery文档